
Advent of 2023, Day 3 – What is lakehouse in Fabric?
This article is originally published at https://tomaztsql.wordpress.com
In this Microsoft Fabric series:
- Dec 01: What is Microsoft Fabric?
- Dec 02: Getting started with Microsoft Fabric
Lakehouse is cost-effective and optimised storage, supporting all types of data and file formats, structured and unstructured data, and helps you govern the data, giving you better data governance. With optimised and concurrent reads and writes, it gives outstanding performance by also reducing data movement and minimising redundant copy operations. Furthermore, it gives you a user-friendly multitasking experience in UI with retaining your context, not losing your running operations and working on multiple things, without accidentally stopping others.
Microsoft Learn puts it nicely: ” Microsoft Fabric Lakehouse is a data architecture platform for storing, managing, and analyzing structured and unstructured data in a single location. It’s a flexible and scalable solution that allows organizations to handle large volumes of data using various tools and frameworks to process and analyze that data. It integrates with other data management and analytics tools to provide a comprehensive solution for data engineering and analytics.“
As a data engineer (role, persona) you will be interacting with lakehouse and using it through the following tools:
- Notebooks
- Pipelines
- Jobs (Apache Spark job definitions)
- Dataflows gen-2
- lakehouse explorer
- Shortcuts
As mentioned above, data engineers can do all the following tasks and/or use the tools for these tasks. It is worth mentioning that under each workspace, you can start a new data engineering task. And lakehouse would be the first one, as being the ground base for any further engineering task.
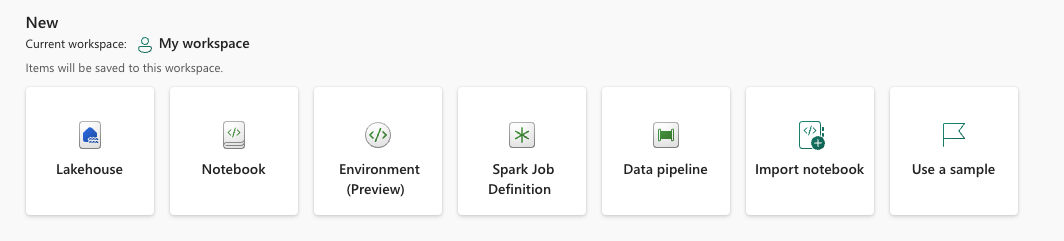
You can always create a new lakehouse within any of the workspaces by simply clicking on “New +”, select “More options” and you will get to this screen.
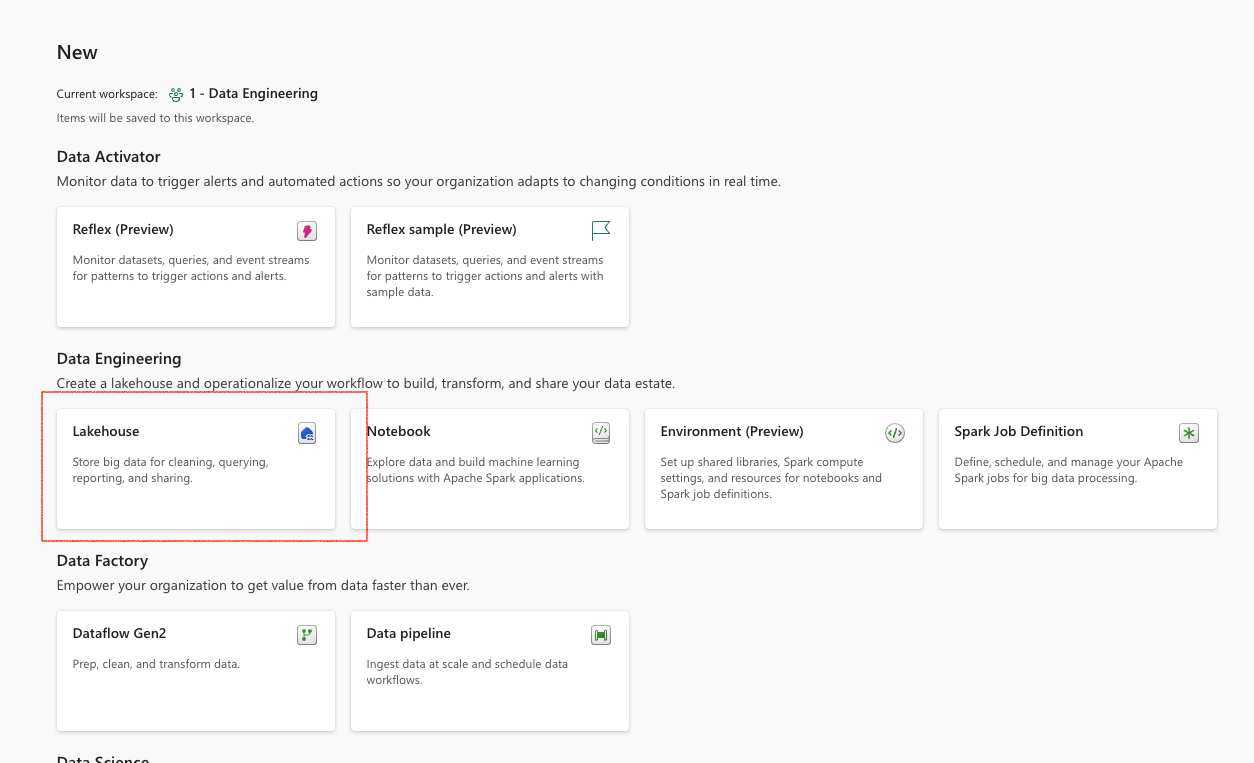
When creating a new lakehouse, you will be prompted to give it a name (in my case, I am choosing the name Advent2023) and you will be greeting with a new UI screen:
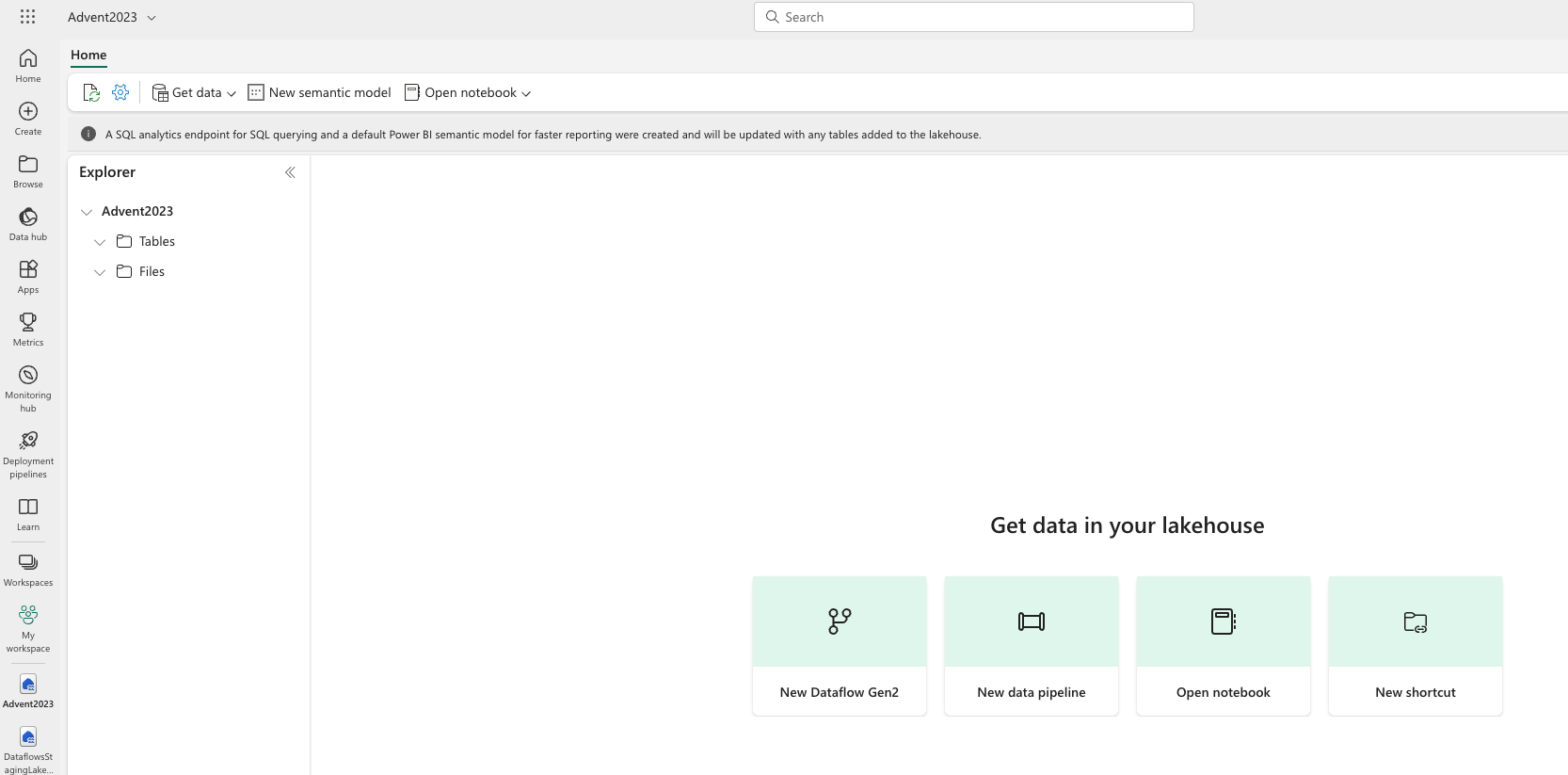
You can get your data into the lakehouse in many ways. On the screen you will have options of getting data:
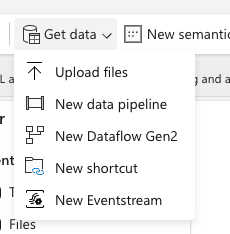
Besides these, you can always use notebooks to get the data and create even SQL Analytics endpoint and semantic model. Both are super important and worth mentioning!
SQL Analytics endpoint
Microsoft Fabrics provides a SQL-based experience for lakehouse delta tables. Delta tables are storing format in lakehouse (like e.g.: Parquet files), enabling capabilities load to table, it is a unified format across whole Fabric and table discovery (part of one-lake metadata foundation). You can analyze data in delta tables using T-SQL language, save functions, generate views, and apply SQL security. To access SQL analytics endpoint, you select a corresponding item in the workspace view or switch to SQL analytics endpoint mode in Lakehouse Explorer. Creating a Lakehouse creates a SQL analytics endpoint, which points to the Lakehouse delta table storage. Once you create a delta table in the Lakehouse, it’s immediately available for querying using the SQL analytics endpoint.
Semantic model
Semantic models are a logical description of an analytical domain, with metrics, business friendly terminology, and representation, to enable deeper analysis. The semantic model is created automatically for you, and the aforementioned business logic gets inherited from the parent lakehouse or Warehouse respectively. It supports Direct lake mode – a new technology, that enables analyzing very large datasets in Power BI, surpassing the limitations of DirectQuery mode, as well as Import mode. Biggest advantage over other modes, is the fact that data is (parquet-formatted files) loaded directly from data lake, without making a copy of data or moving data into Power BI semantic model.
To finalize – biggest difference between lakehouse, data lake and datawarehouse
We will also do a comparison between the data lakehouse, data warehouse and data lake. Briefly, the biggest differences are: that data lakes lack governance, security and ACID transactions. Data warehouses lack flexibility, scaling and ingress of unstructured data. Lakehouse should cover ACID transactions, enforce governance and at the same time give scalability.
Tomorrow we will look into the Delta tables!
Complete set of code, documents, notebooks, and all of the materials will be available at the Github repository: https://github.com/tomaztk/Microsoft-Fabric
Happy Advent of 2023! 
Thanks for visiting r-craft.org
This article is originally published at https://tomaztsql.wordpress.com
Please visit source website for post related comments.