
Advent of 2023, Day 24 – OneLake in Fabric
This article is originally published at https://tomaztsql.wordpress.com
In this Microsoft Fabric series:
- Dec 01: What is Microsoft Fabric?
- Dec 02: Getting started with Microsoft Fabric
- Dec 03: What is lakehouse in Fabric?
- Dec 04: Delta lake and delta tables in Microsoft Fabric
- Dec 05: Getting data into lakehouse
- Dec 06: SQL Analytics endpoint
- Dec 07: SQL commands in SQL Analytics endpoint
- Dec 08: Using Lakehouse REST API
- Dec 09: Building custom environments
- Dec 10: Creating Job Spark definition
- Dec 11: Starting data science with Microsoft Fabric
- Dec 12: Creating data science experiments with Microsoft Fabric
- Dec 13: Creating ML Model with Microsoft Fabric
- Dec 14: Data warehouse with Microsoft Fabric
- Dec 15: Building warehouse with Microsoft Fabric
- Dec 16: Creating data pipelines for Fabric data warehouse
- Dec 17: Exploring Power BI in Microsoft Fabric
- Dec 18: Exploring Power BI in Microsoft Fabric
- Dec 19: Event streaming with Fabric
- Dec 20: Working with notebooks in Fabric
- Dec 21: Monitoring workspaces with Fabric
- Dec 22: Apps in Fabric
- Dec 23: Admin Portal in Fabric
OneLake comes automatically with every Microsoft Fabric tenant and represents a single, logical data lake. Its main features are its unification and one copy of data across the organization and multiple analytical engines.
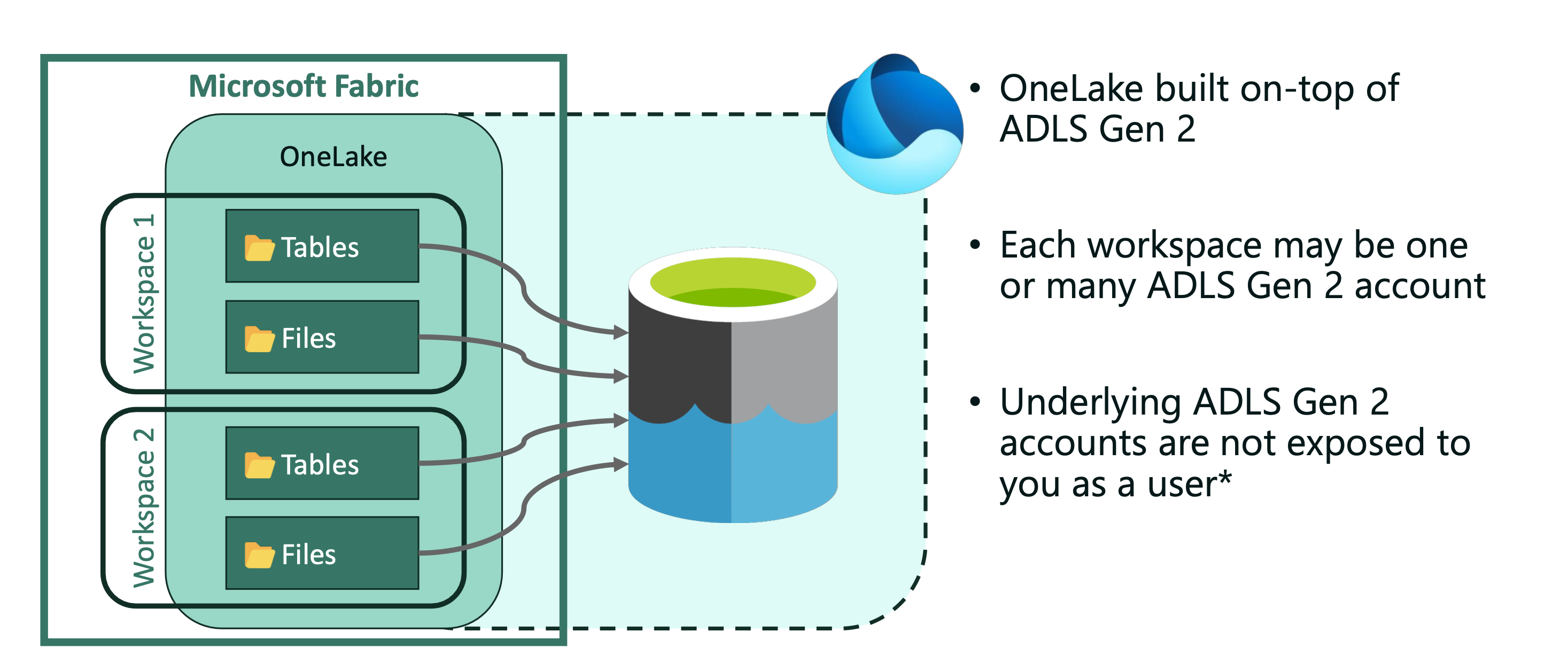
OneLake is built on ADLS Gen2 (Azure Data Lake Storage) and supports any type of files, structured or unstructured.Data warehouses and lakehouses automatically store data in OneLake in parquet format (Delta Lake, and delta parquet file format). This way OneLake makes a better shift from the Synapse experience (Dedicated and Serverless pools).
The open data format is what OneLake brings to the table. No vendor lock in and useses Delta format, in an open data lake – OneLake on highly compressed parquet files.
Support for the ADLS Gen2 APIs and SKDs makes OneLake integration even better, where you can connect to Azure Synapse Analytics, Azure storage Explorer, Azure Databricks (DFS API) and Azure HDInsight. But still the data will remain within the same OneLake, same goes for Workspaces – they will be appear as containers within storage account, and different data items appear as folders within those containers.
One copy of data
OneLake aims to give you the most value possible out of a single copy of data without data movement or duplication. You no longer need to copy data just to use it with another engine or to break down silos so you can analyze the data with data from other sources.
Shortcuts
Shortcuts in Microsoft OneLake are objects that allow you to unify your data across domains, clouds, and accounts by creating a single virtual data lake for your entire enterprise. They are pointers (with target path, security and RLS) to other storage location (Azure, AWS, OneLake) and give you Fabric experiences over all analytical engines. Each shortcut will appear as a folder in OneLake, and are symbolic representation of source data; meaning if you delete a shortcut, the origin data will remain intact. Shortcuts eliminate edge copies of data and reduce process latency associated with data copies and staging.
Some of the best-practices in OneLake
Couple of practices that might improve your OneLake experience.
- Bring as much of apps, access, reports and clients closer to your Fabric; in best scenarios, collocate them
- Use as much shortcuts as you want, but data that is used frequently could have a copy in sparsed format
- Use CTAS instead of DELETE statements
- When creating and using Domains, try to do it per business entities.
- OneLake accepts all formats, but consider choosing your optimal data type for improved performance
- Splitting files when using COPY INTO into smaller chunks.
Tomorrow we will look into Fabric documentation.
Complete set of code, documents, notebooks, and all of the materials will be available at the Github repository: https://github.com/tomaztk/Microsoft-Fabric
Happy Advent of 2023! 
Thanks for visiting r-craft.org
This article is originally published at https://tomaztsql.wordpress.com
Please visit source website for post related comments.