
Twitter sentiment analysis with Machine Learning in R using doc2vec approach (part 1)
This article is originally published at https://www.analyzecore.com
We will use Document-Term Matrix that is the result of Vocabulary-based vectorization for training the model for Twitter sentiment analysisRecently I’ve worked with word2vec and doc2vec algorithms that I found interesting from many perspectives. Even though I used them for another purpose, the main thing they were developed for is Text analysis. As I noticed, my 2014 year’s article Twitter sentiment analysis is one of the most popular blog posts on the blog even today.
The problem with the previous method is that it just computes the number of positive and negative words and makes a conclusion based on their difference. Therefore, when using a simple vocabularies approach for a phrase “not bad” we’ll get a negative estimation.
But doc2vec is a deep learning algorithm that draws context from phrases. It’s currently one of the best ways of sentiment classification for movie reviews. You can use the following method to analyze feedbacks, reviews, comments, and so on. And you can expect better results comparing to tweets analysis because they usually include lots of misspelling.
We’ll use tweets for this example because it’s pretty easy to get them via Twitter API. We only need to create an app on https://dev.twitter.com (My apps menu) and find an API Key, API secret, Access Token and Access Token Secret on Keys and Access Tokens menu tab.
First, I’d like to give a credit to Dmitry Selivanov, the author of the great text2vec R package that we’ll use for sentiment analysis.
You can download a set of 1.6 million classified tweets here and use them to train a model. Before we start the analysis, I want to point your attention to how tweets were classified. There are two grades of sentiment: 0 (negative) and 4 (positive). That means that they are not neutral. I suggest using a probability of positiveness instead of class. In this case, we’ll get a range of values from 0 (completely negative) to 1 (completely positive) and assume that values from 0.35 to 0.65 are somewhere in the middle and they are neutral.
The following is the R code for training the model using Document-Term Matrix (DTM) that is the result of Vocabulary-based vectorization. In addition, we will use TF-IDF method for text preprocessing. Note that model training can take up to an hour, depending on computer’s configuration:
click to expand R code
# loading packages
library(twitteR)
library(ROAuth)
library(tidyverse)
library(purrrlyr)
library(text2vec)
library(caret)
library(glmnet)
library(ggrepel)
### loading and preprocessing a training set of tweets
# function for converting some symbols
conv_fun <- function(x) iconv(x, "latin1", "ASCII", "")
##### loading classified tweets ######
# source: http://help.sentiment140.com/for-students/
# 0 - the polarity of the tweet (0 = negative, 4 = positive)
# 1 - the id of the tweet
# 2 - the date of the tweet
# 3 - the query. If there is no query, then this value is NO_QUERY.
# 4 - the user that tweeted
# 5 - the text of the tweet
tweets_classified <- read_csv('training.1600000.processed.noemoticon.csv', col_names = c('sentiment', 'id', 'date', 'query', 'user', 'text')) %>%
# converting some symbols
dmap_at('text', conv_fun) %>%
# replacing class values
mutate(sentiment = ifelse(sentiment == 0, 0, 1))
# there are some tweets with NA ids that we replace with dummies
tweets_classified_na <- tweets_classified %>%
filter(is.na(id) == TRUE) %>%
mutate(id = c(1:n()))
tweets_classified <- tweets_classified %>%
filter(!is.na(id)) %>%
rbind(., tweets_classified_na)
# data splitting on train and test
set.seed(2340)
trainIndex <- createDataPartition(tweets_classified$sentiment, p = 0.8,
list = FALSE,
times = 1)
tweets_train <- tweets_classified[trainIndex, ]
tweets_test <- tweets_classified[-trainIndex, ]
##### Vectorization #####
# define preprocessing function and tokenization function
prep_fun <- tolower
tok_fun <- word_tokenizer
it_train <- itoken(tweets_train$text,
preprocessor = prep_fun,
tokenizer = tok_fun,
ids = tweets_train$id,
progressbar = TRUE)
it_test <- itoken(tweets_test$text,
preprocessor = prep_fun,
tokenizer = tok_fun,
ids = tweets_test$id,
progressbar = TRUE)
# creating vocabulary and document-term matrix
vocab <- create_vocabulary(it_train)
vectorizer <- vocab_vectorizer(vocab)
dtm_train <- create_dtm(it_train, vectorizer)
# define tf-idf model
tfidf <- TfIdf$new()
# fit the model to the train data and transform it with the fitted model
dtm_train_tfidf <- fit_transform(dtm_train, tfidf)
# apply pre-trained tf-idf transformation to test data
dtm_test_tfidf <- create_dtm(it_test, vectorizer) %>%
transform(tfidf)
# train the model
t1 <- Sys.time()
glmnet_classifier <- cv.glmnet(x = dtm_train_tfidf,
y = tweets_train[['sentiment']],
family = 'binomial',
# L1 penalty
alpha = 1,
# interested in the area under ROC curve
type.measure = "auc",
# 5-fold cross-validation
nfolds = 5,
# high value is less accurate, but has faster training
thresh = 1e-3,
# again lower number of iterations for faster training
maxit = 1e3)
print(difftime(Sys.time(), t1, units = 'mins'))
plot(glmnet_classifier)
print(paste("max AUC =", round(max(glmnet_classifier$cvm), 4)))
preds <- predict(glmnet_classifier, dtm_test_tfidf, type = 'response')[ ,1]
auc(as.numeric(tweets_test$sentiment), preds)
# save the objects for future using
rm(list = setdiff(ls(), c('glmnet_classifier', 'conv_fun', 'prep_fun', 'tok_fun', 'vectorizer', 'tfidf')))
save.image('image.RData')
rm(list = ls())
#######################################################
As you can see, both AUC on train and test datasets are pretty high (0.876 and 0.875). Note that we saved the model and you don’t need to train it every time you need to assess some tweets. Next time you do sentiment analysis, you can start with the script below.
Ok, once we have model trained and validated, we can use it. For this, we start with tweets fetching via Twitter API and preprocessing in the same way as with classified tweets. For instance, the company I work for has just released an ambitious product for Mac users and it’s interesting to analyze how tweets about Setapp are rated.
click to expand R code
load('image.RData')
### fetching tweets ###
download.file(url = "http://curl.haxx.se/ca/cacert.pem",
destfile = "cacert.pem")
setup_twitter_oauth('your_api_key', # api key
'your_api_secret', # api secret
'your_access_token', # access token
'your_access_token_secret' # access token secret
)
df_tweets <- twListToDF(searchTwitter('setapp OR #setapp', n = 1000, lang = 'en')) %>%
# converting some symbols
dmap_at('text', conv_fun)
# preprocessing and tokenization
it_tweets <- itoken(df_tweets$text,
preprocessor = prep_fun,
tokenizer = tok_fun,
ids = df_tweets$id,
progressbar = TRUE)
# creating vocabulary and document-term matrix
dtm_tweets <- create_dtm(it_tweets, vectorizer)
# transforming data with tf-idf
dtm_tweets_tfidf <- fit_transform(dtm_tweets, tfidf)
# predict probabilities of positiveness
preds_tweets <- predict(glmnet_classifier, dtm_tweets_tfidf, type = 'response')[ ,1]
# adding rates to initial dataset
df_tweets$sentiment <- preds_tweets
And finally, we can visualize the result with the following code:
click to expand R code
# color palette
cols <- c("#ce472e", "#f05336", "#ffd73e", "#eec73a", "#4ab04a")
set.seed(932)
samp_ind <- sample(c(1:nrow(df_tweets)), nrow(df_tweets) * 0.1) # 10% for labeling
# plotting
ggplot(df_tweets, aes(x = created, y = sentiment, color = sentiment)) +
theme_minimal() +
scale_color_gradientn(colors = cols, limits = c(0, 1),
breaks = seq(0, 1, by = 1/4),
labels = c("0", round(1/4*1, 1), round(1/4*2, 1), round(1/4*3, 1), round(1/4*4, 1)),
guide = guide_colourbar(ticks = T, nbin = 50, barheight = .5, label = T, barwidth = 10)) +
geom_point(aes(color = sentiment), alpha = 0.8) +
geom_hline(yintercept = 0.65, color = "#4ab04a", size = 1.5, alpha = 0.6, linetype = "longdash") +
geom_hline(yintercept = 0.35, color = "#f05336", size = 1.5, alpha = 0.6, linetype = "longdash") +
geom_smooth(size = 1.2, alpha = 0.2) +
geom_label_repel(data = df_tweets[samp_ind, ],
aes(label = round(sentiment, 2)),
fontface = 'bold',
size = 2.5,
max.iter = 100) +
theme(legend.position = 'bottom',
legend.direction = "horizontal",
panel.grid.major = element_blank(),
panel.grid.minor = element_blank(),
plot.title = element_text(size = 20, face = "bold", vjust = 2, color = 'black', lineheight = 0.8),
axis.title.x = element_text(size = 16),
axis.title.y = element_text(size = 16),
axis.text.y = element_text(size = 8, face = "bold", color = 'black'),
axis.text.x = element_text(size = 8, face = "bold", color = 'black')) +
ggtitle("Tweets Sentiment rate (probability of positiveness)")
{kind=link}
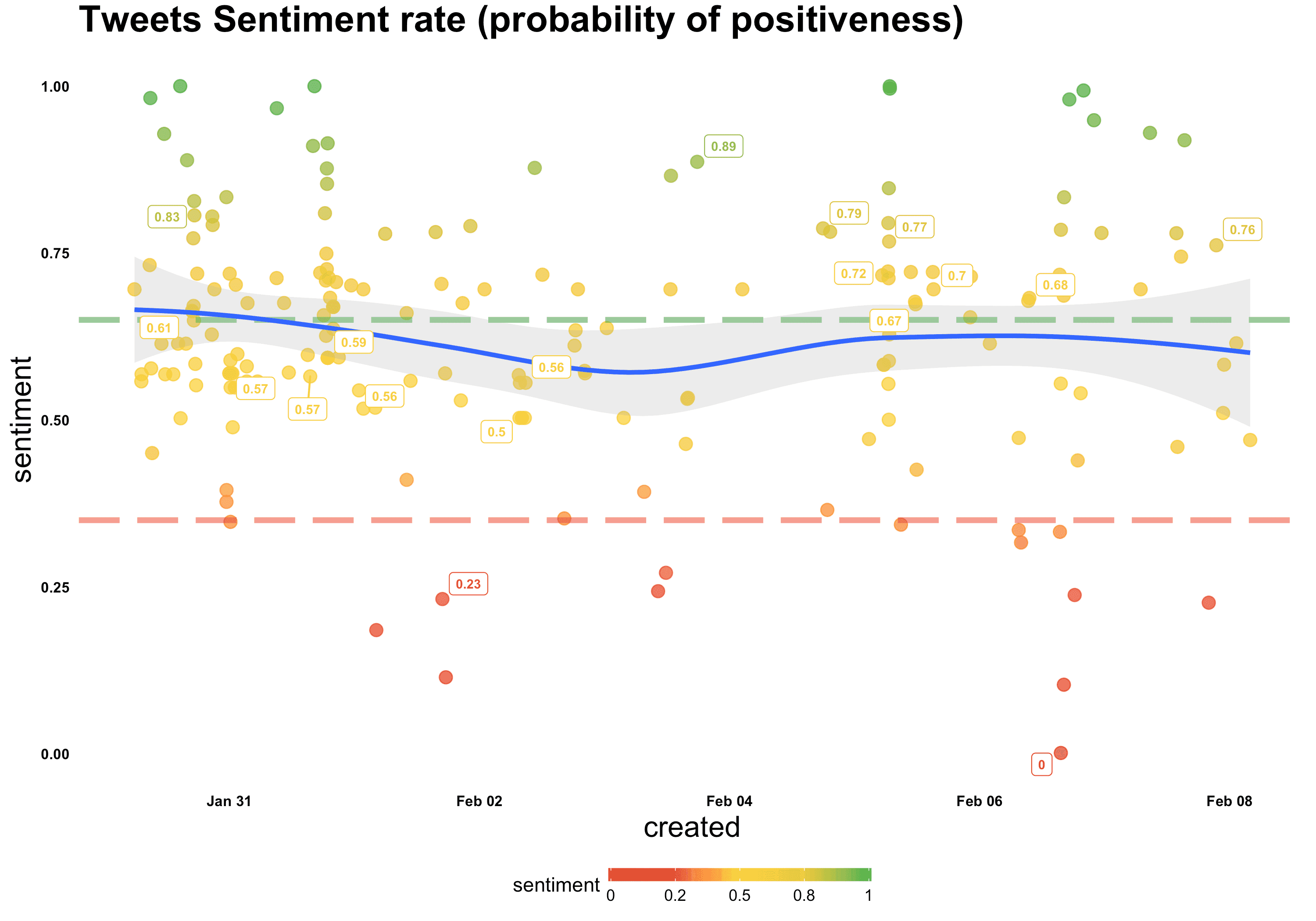
The green line is the boundary of positive tweets and the red one is the boundary of negative tweets. In addition, tweets are colored with red (negative), yellow (neutral) and green (positive) colors. As you can see, most of the tweets are around the green boundary and it means that they tend to be positive.
To be continued…
The post Twitter sentiment analysis with Machine Learning in R using doc2vec approach (part 1) appeared first on AnalyzeCore by Sergey Bryl' - data is beautiful, data is a story.
Thanks for visiting r-craft.org
This article is originally published at https://www.analyzecore.com
Please visit source website for post related comments.