
Blocked Gibbs Sampling in R for Bayesian Multiple Linear Regression
This article is originally published at https://stablemarkets.wordpress.com
In a previous post, I derived and coded a Gibbs sampler in R for estimating a simple linear regression.
In this post, I will do the same for multivariate linear regression. I will derive the conditional posterior distributions necessary for the blocked Gibbs sampler. I will then code the sampler and test it using simulated data.
R code for simulating data and implementing the blocked Gibbs is in by GitHub repo.
A Bayesian Model
Suppose we have a sample size of  subjects. We observe an
subjects. We observe an  outcome vector
outcome vector  . The Bayesian multivariate regression assumes that this vector is drawn from a multivariate normal distribution where the mean vector is
. The Bayesian multivariate regression assumes that this vector is drawn from a multivariate normal distribution where the mean vector is  and covariance matrix
and covariance matrix  . Here,
. Here,  is an observed
is an observed  matrix of covariates. Note, the first column of this matrix is identity. The parameter vector
matrix of covariates. Note, the first column of this matrix is identity. The parameter vector  is
is  ,
,  is a common variance parameter, and
is a common variance parameter, and  is the
is the  identity matrix. By using the identity matrix, we are assuming independent observations. Formally,
identity matrix. By using the identity matrix, we are assuming independent observations. Formally,
")
So far, this is identical to the multivariate normal regression seen in the frequentist setting. Assuming  is full column rank, maximizing the likelihood yields the solution:
is full column rank, maximizing the likelihood yields the solution:
^{-1}X'y")
A Bayesian model is obtained by specifying a prior distribution for and . For this example, I will use a flat, improper prior for and a inverse gamma prior for :
 \propto 1")
")
We assume the hyperparamters are known for simplicity.
Joint Posterior Distribution
The joint posterior distribution is proportional to
 \propto p(y | \beta, \phi, X) p(\beta|X) p(\phi| X)")
We can write this because we assumed prior independence. That is,
 = p(\beta|X) p(\phi|X)") .
.
Substituting the distributions,
 \propto \phi^{-n/2} e^{-\frac{1}{2\phi}(y - X\beta)'(y - X\beta) } \phi^{-(\alpha + 1)}e^{-\frac{\gamma}{\phi}}")
Blocked Gibbs Sampler
Before coding the sampler, we need to derive the components of the Gibbs sampler – the posterior conditional distributions of each parameter.
The conditional posterior of  is found by dropping factors independent of from the joint posterior and rearranging. This case is easy since there’s nothing to drop:
is found by dropping factors independent of from the joint posterior and rearranging. This case is easy since there’s nothing to drop:
![\begin{aligned} p(\phi | \beta, \alpha, \gamma, y, X) & \propto \phi^{-n/2} e^{-\frac{1}{2\phi}(y - X\beta)'(y - X\beta) } \phi^{-(\alpha + 1)}e^{-\frac{\gamma}{\phi}} \\ & \propto \phi^{-(\alpha + \frac{n}{2} + 1)} e^{-\frac{1}{\phi}\Big[ \frac{1}{2}(y - X\beta)'(y - X\beta) + \gamma \Big] } \\ & = IG(shape=\alpha + \frac{n}{2}, rate=\frac{1}{2}(y - X\beta)'(y - X\beta) + \gamma) \end{aligned}](https://s0.wp.com/latex.php?latex=%5Cbegin%7Baligned%7D+p%28%5Cphi+%7C+%5Cbeta%2C+%5Calpha%2C+%5Cgamma%2C+y%2C+X%29+%26+%5Cpropto%C2%A0%5Cphi%5E%7B-n%2F2%7D+e%5E%7B-%5Cfrac%7B1%7D%7B2%5Cphi%7D%28y+-+X%5Cbeta%29%27%28y+-+X%5Cbeta%29+%7D+%5Cphi%5E%7B-%28%5Calpha+%2B+1%29%7De%5E%7B-%5Cfrac%7B%5Cgamma%7D%7B%5Cphi%7D%7D+%5C%5C+%26+%5Cpropto+%5Cphi%5E%7B-%28%5Calpha+%2B+%5Cfrac%7Bn%7D%7B2%7D+%2B+1%29%7D+e%5E%7B-%5Cfrac%7B1%7D%7B%5Cphi%7D%5CBig%5B+%5Cfrac%7B1%7D%7B2%7D%28y+-+X%5Cbeta%29%27%28y+-+X%5Cbeta%29+%2B+%5Cgamma+%5CBig%5D+%7D+%5C%5C+%26+%3D+IG%28shape%3D%5Calpha+%2B+%5Cfrac%7Bn%7D%7B2%7D%2C+rate%3D%5Cfrac%7B1%7D%7B2%7D%28y+-+X%5Cbeta%29%27%28y+-+X%5Cbeta%29+%2B+%5Cgamma%29+%5Cend%7Baligned%7D+&bg=ffffff&%23038;fg=000000&%23038;s=0 "\begin{aligned} p(\phi | \beta, \alpha, \gamma, y, X) & \propto \phi^{-n/2} e^{-\frac{1}{2\phi}(y - X\beta)'(y - X\beta) } \phi^{-(\alpha + 1)}e^{-\frac{\gamma}{\phi}} \\ & \propto \phi^{-(\alpha + \frac{n}{2} + 1)} e^{-\frac{1}{\phi}\Big[ \frac{1}{2}(y - X\beta)'(y - X\beta) + \gamma \Big] } \\ & = IG(shape=\alpha + \frac{n}{2}, rate=\frac{1}{2}(y - X\beta)'(y - X\beta) + \gamma) \end{aligned}")
The conditional posterior of  takes some more linear algebra.
takes some more linear algebra.
 & \propto e^{-\frac{1}{2\phi}(y - X\beta)'(y - X\beta) } \\ & \propto e^{-\frac{1}{2\phi}( y'y - 2\beta'X'y + \beta'X'X\beta ) } \\ & \propto e^{-\frac{1}{2\phi}(\beta'X'X\beta - 2\beta'X'y ) } \\ & \propto e^{-\frac{1}{2\phi}(\beta'X'X\beta - 2\beta'(X'X)(X'X)^{-1}X'y ) } \\ & \propto e^{-\frac{1}{2\phi}(\beta - (X'X)^{-1}X'y )'(X'X)(\beta - (X'X)^{-1}X'y )} \\ & = N_p((X'X)^{-1}X'y, \phi (X'X)^{-1} )\end{aligned}")
This is a really nifty and intuitive result. Because we use a flat prior on the parameter vector, the conditional posterior of the parameter vector is centered around the maximum likelihood estimate . The covariance matrix of the conditional posterior is the frequentist estimate of the covariance matrix,  = \phi (X'X)^{-1}")
Also note that the conditional posterior is a multivariate distribution since is a vector. So in each iteration of the Gibbs sampler, we draw a whole vector, or “block”, from the posterior. This is much more efficient than drawing from the conditional distribution of each parameter conditional on the others, one at a time. This is why the procedure is called a “blocked” sampler.
Simulation
All code referencing in the following can be found in my GitHub repo.
I simulate a  outcome vector from
outcome vector from ") . Here is the
. Here is the  identity matrix and is a
identity matrix and is a  model matrix. The true parameter vector, is
model matrix. The true parameter vector, is
 \ '")
Running the blocked Gibbs sampler (the block_gibbs() function) produces estimates of the true coefficient and variance parameters. 500,000 iterations were run. A burn-in period of 100,000 with a trimming of 10 iterations.
Below are the plots of the MCMC chains with true values indicated with a red line.

Here are the posterior distributions of the parameters after applying burn-in and trimming:

Seems like we’re able to get reasonable posterior estimates of these parameters. The distributions are not exactly centered around the truth because our data set is only one realization of the truth. To make sure the Bayesian estimator is working properly, I repeat this exercise for 1,000 simulated datasets.
This will yield a 1,000 sets of posterior means and 1,000 sets of 95% credible intervals. On average, these 1,000 posterior means should be centered around the truth. And on average the true parameter values should be within the credible interval 95% of the time.
Below is a summary of these evaluations.
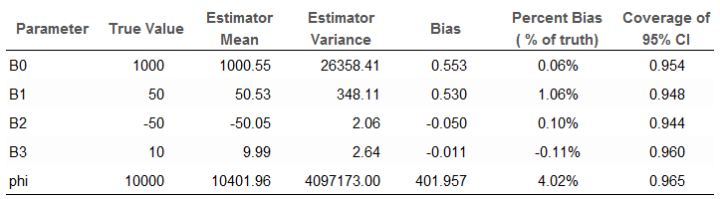
The “Estimator Means” column is the average posterior mean across all 1,000 simulations. Pretty good. The percent bias is all less than 5%. The coverage of the 95% CI is around 95% for all parameters.
Extensions
There are many extensions we can make to this model. For example, other distributions aside from the Normal could be used in order to accommodate different types of outcomes. For example, if we had binary data, we could model it as:
")
 = X\beta")
And then place a prior distribution on . This idea generalizes Bayesian linear regression to Bayesian GLM.
In the linear case outlined in this post, it’s possible to have modeled the covariance matrix more flexibly. Instead, it is assumed that the covariance matrix is diagonal with a single common variance. This is the homoskedasticity assumption made in multiple linear regression. If the data is clustered (e.g., multiple observations per subject), we could use an inverse-Wishart distribution to model the whole covariance matrix.
Thanks for visiting r-craft.org
This article is originally published at https://stablemarkets.wordpress.com
Please visit source website for post related comments.