
Advent of 2023, Day 14 – Data warehouse with Microsoft Fabric
This article is originally published at https://tomaztsql.wordpress.com
In this Microsoft Fabric series:
- Dec 01: What is Microsoft Fabric?
- Dec 02: Getting started with Microsoft Fabric
- Dec 03: What is lakehouse in Fabric?
- Dec 04: Delta lake and delta tables in Microsoft Fabric
- Dec 05: Getting data into lakehouse
- Dec 06: SQL Analytics endpoint
- Dec 07: SQL commands in SQL Analytics endpoint
- Dec 08: Using Lakehouse REST API
- Dec 09: Building custom environments
- Dec 10: Creating Job Spark definition
- Dec 11: Starting data science with Microsoft Fabric
- Dec 12: Creating data science experiments with Microsoft Fabric
- Dec 13: Creating ML Model with Microsoft Fabric
Today we will start exploring the Fabric Data Warehouse.
With the data lake-centric logic, the data warehouse in Fabric is built on a distributed processing engine, that enables automated scaling. The SaaS experience creates a segway to easier analysis and reporting, and at the same time gives the ability to run heavy workloads against open data format, simply by using transact SQL (T-SQL). Microsoft OneLake gives all the services to hold a single copy of data and can be consumed in a data warehouse, datalake or SQL Analytics.
Building a data warehouse from scratch is not an easy task. Not only that you need to understand the data engineering concepts, data pipelines, tables, and modelling, but you also need to know the architecture, design and domain/business processes and logic.
Fabric warehouse makes these tasks more collaborative due to the workspaces, and unifies the experience, regardless of the tool. Many of these tools and offerings are simplified (and I use this word with caution) due to the skills and roles that Fabric tends to offer and bring closer together. you can be a DBA or a T-SQL developer, the shared experience will be the same. You can be a citizen developer, or Power BI user, and the data insights will be delivered to you faster due to the same experience and OneLake architecture.
Furthermore, the improved datalake (primarily data scientists and analysts) reading data from the data lake (folders, parquet files, csv) is making the canonical warehouse open to faster changes, and making the warehouse easier updatable (adding a dimension, and column to the fact table, adding calculation). All of a sudden, teams that are extracting insights from data have the capabilities to get the semi-structured data from the datalake and combine the data/datasets with canonical (and mostly “relational”) warehouse and data formats.
Fabric gives ability to get data from any source. If the drivers / plug-ins for data sources are not available, shortcuts is the next best thing. And the background processes sync metadata layer every 10 seconds and checks for any updates (e.g.: read data from AWS S3 to Microsoft Fabric). This means, that you can create a virtual data warehouse by creating shortcuts to their data wherever it resides. A virtual warehouse can consist of data from OneLake, Azure Data Lake Storage, or any other cloud vendor storage within a single boundary and with no data duplication. Data stored in all these different sources can be easily joined, there were previously not that straightforward and required additional tasks.
Fabric warehouse can be also queried in SSMS (SQL Server Management studio) or directly in the Fabric warehouse
Technology
Microsoft Fabric with Onelake is built on top of the parquet file format. Data in the Warehouse are also stored in parquet file format, and published as Delta Lake, enabling all the Delta benefits (ACID transactions, travel in time, schema evaluation, …). Therefore, all the data can be prepared using Spark, and Python through pipelines, COPY format, and notebooks. The best advantage of this format is that you only have one (!) copy of data and Delta Lake logs. Similar to SQL Server 
OneLake provides storage and there is also a compute capacity. Both are decoupled in a data warehouse; and therefore, the scalability is instant, to deliver the results to the end user. Finding and choosing the correct capacity is also important from a cost and performance perspective.
In general, the capabilities for warehouse are the following:
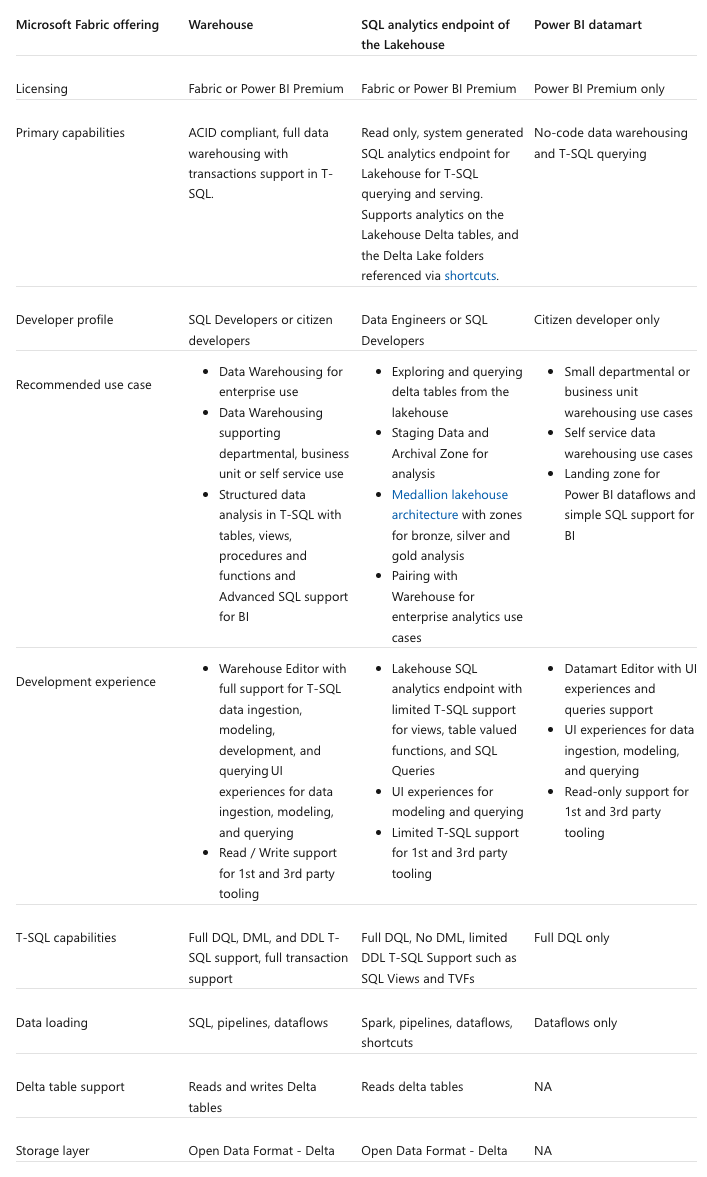
(Source: Microsoft Learn)
And in terms of the store, this is a nice comparison:
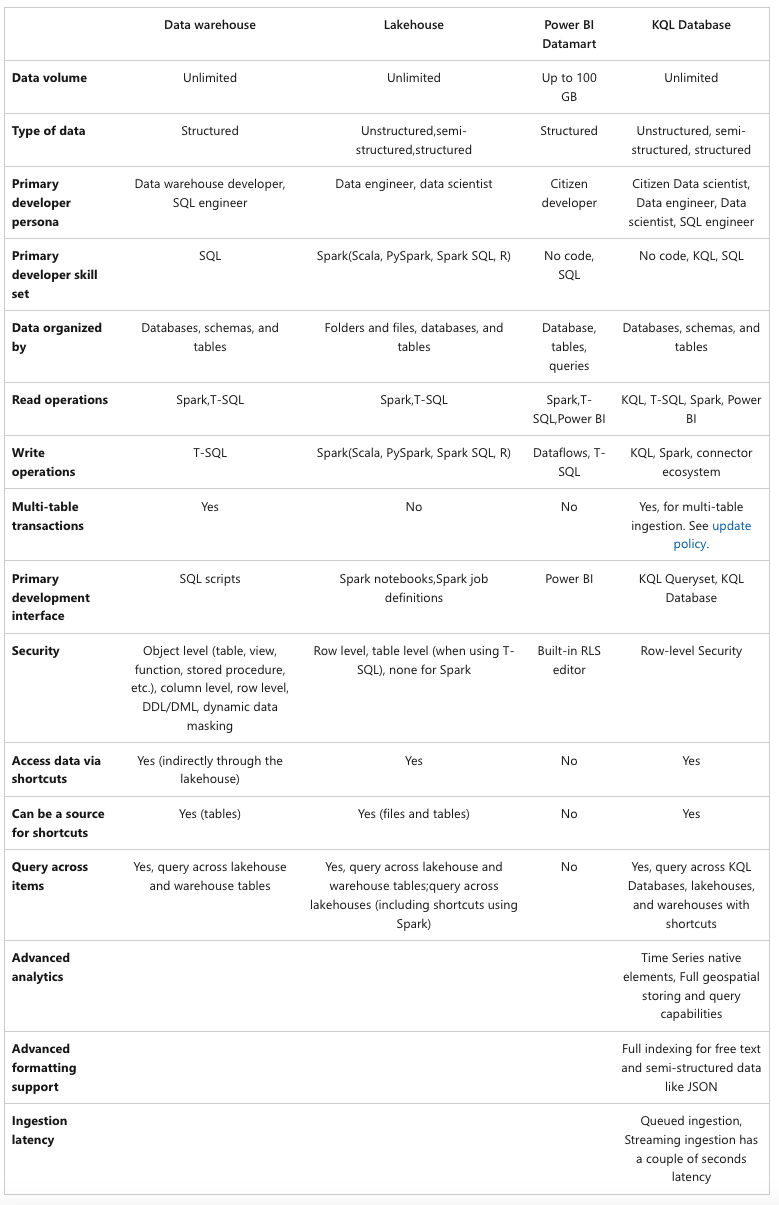
(Source: Microsoft Learn)
Tomorrow we will start looking at building the components, as we have looked into some basic concepts today.
Complete set of code, documents, notebooks, and all of the materials will be available at the Github repository: https://github.com/tomaztk/Microsoft-Fabric
Happy Advent of 2023!
Thanks for visiting r-craft.org
This article is originally published at https://tomaztsql.wordpress.com
Please visit source website for post related comments.